
1. BERT의 구조 개요
2. BERT 모델의 구조
3. BERT의 학습 방식
4. BERT와 GPT 비교

이번 포스팅에서는 BERT의 구조에 대해서 설명하겠습니다.
1. BERT의 구조 개요
- 트랜스포머의 인코더 부분만 사용
- 두 가지 방의 사전학습 방법 이용
- Masked Language Model (MLM): 문장 중간을 마스킹 처리하고 해당 단어를 맞추는 학습
- Next Sentence Prediction (NSP): 두 문장이 관계가 있는지 없는지를 학습
- 이를 통해 문장의 앞 뒤 문맥에 따른 예측이 가능
- 입력값은 토큰 임베딩, 문장 세그먼트 임베딩, 포지션 임베딩을 합친 벡터로 최대 길이는 512
2. BERT 모델의 구조
BERT는 트랜스포머의 인코더 부분만을 사용한 언어 모델 입니다.
BERT는 주어진 텍스트의 문맥을 양방향으로 이해하는데 특화되어 있습니다.
BERT 모델은 크기에 따라 두 가지 주요 버전을 제공합니다.
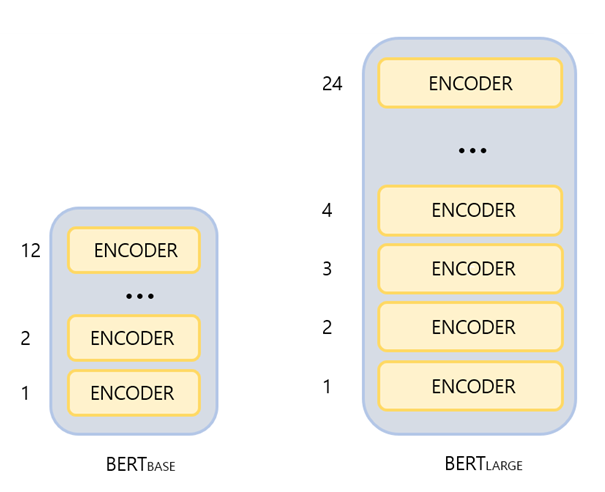
- BERT_base:
- L=12
- H=768
- A=12
- 총 파라미터 수: 1억 1천만 개 (110M)
- BERT_large:
- L=24
- H=1024
- A=16
- 총 파라미터 수: 3억 4천만 개 (340M)
여기서 L은 트랜스포머 인코더 블록의 레이어 수, H는 히든 레이어 크기, A는 셀프 어텐션 헤드의 개수를 나타냅니다. BERT는 대소문자를 구별하는 버전(cased)과 모두 소문자로 변환하는(uncased) 버전으로 제공되어 사용 목적에 따라 적절한 버전을 사용할 수 있습니다.
3. BERT의 학습 방식
BERT는 두 가지 주요 사전 학습(Pre-training) 과정을 거칩니다:
- Masked Language Modeling (MLM): 입력 문장에서 무작위로 일부 단어를 [MASK] 토큰으로 마스킹하고, 모델이 이 마스킹된 단어들을 예측하도록 합니다. 이는 모델이 문맥을 양방향으로 이해하도록 돕습니다.
- Next Sentence Prediction (NSP): 두 문장이 연속되는 문장인지 아닌지를 예측하는 과정을 통해, 문장 간의 관계를 학습합니다.
이 두 가지 학습 방법은 BERT가 문맥을 보다 깊이 이해할 수 있도록 합니다.
4. BERT와 GPT 비교
- OpenAI GPT: 다음 토큰을 예측하는 기본적인 언어 모델링 방식을 사용하며, 트랜스포머의 디코더 구조를 활용합니다. GPT는 단방향(왼쪽에서 오른쪽)으로만 문맥을 이해합니다.
- BERT: 마스킹된 단어 예측(MLM)과 다음 문장 예측(NSP)을 위해 트랜스포머의 인코더 구조를 사용합니다. 이는 양방향으로 문맥을 이해할 수 있게 합니다.
BERT base 모델의 경우, OpenAI의 GPT모델과 hyper parameter가 동일하지만 사전 학습 개념을 바꾸어 높은 성능을 보입니다. 이는 동일한 하이퍼파라미터라도 학습 방식에 따라 성능이 달라질 수 있음을 보여줍니다.
특히 BERT는 문장 분류, 감정 분석, 질의 응답, 개체명 인식 등의 작업에서 높은 성능을 보입니다.
이상 BERT의 구조에 대해서 알아보았습니다.
트랜스포머
2. 트랜스포머 구조 (Transformer High-level Architecture)
3. 트랜스포머 구조 상세 (Transformer Detailed Architecture)
4. 트랜스포머 훈련과 예측 단계 (Transformer Learning and Inference Step)
5. 트랜스포머 입력과 출력 (Transformer Input and Output)
6. 어텐션, 셀프 어텐션, 멀티 헤드 어텐션 개요 (Transformer Attention, Self Attention, Multi-head Attention)
7. 셀프 어텐션 상세 동작 과정 (Transformer Self Attention Detailed Process)
8. 멀티 헤드 어텐션 상세 동작 과정 (Transformer Multi-head Attention Detailed Process)
BERT
Comment