

이번 포스팅에서는 트랜스포머의 인코더, 디코더에 대해서 더 상세하게 알아보겠습니다.
트랜스포머의 상세 구조
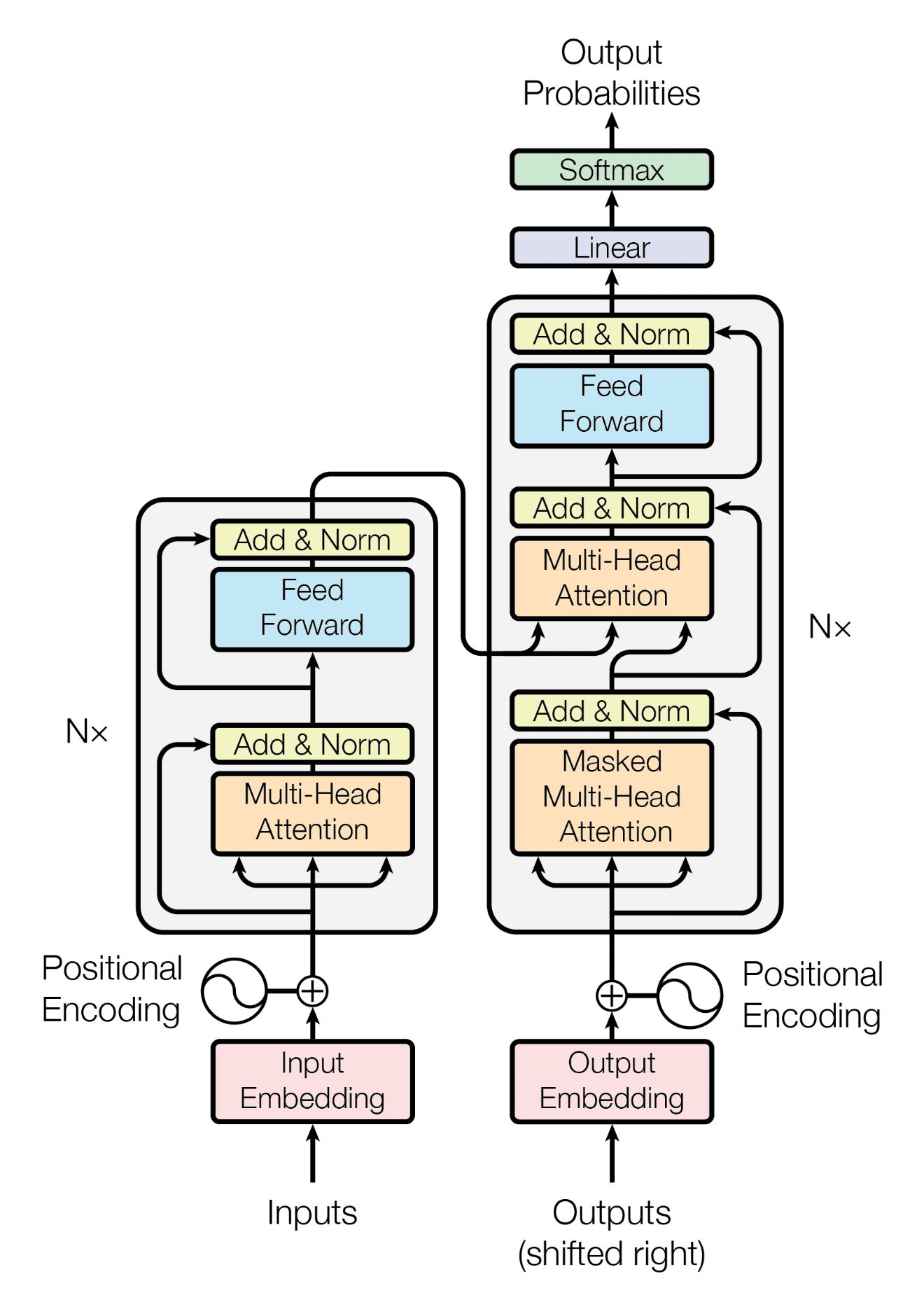
트랜스포머는 크게 인코더와 디코더 두 부분으로 나뉩니다. 인코더, 디코더는 여러 개의 동일한 레이어로 구성되어 있으며, 이러한 레이어들이 N번 겹쳐 있는 구조를 가집니다(Nx). 이제 트랜스포머의 각 구성요소에 대해서 좀 더 자세히 알아보겠습니다.
포지셔널 인코딩 (Positional Encoding)
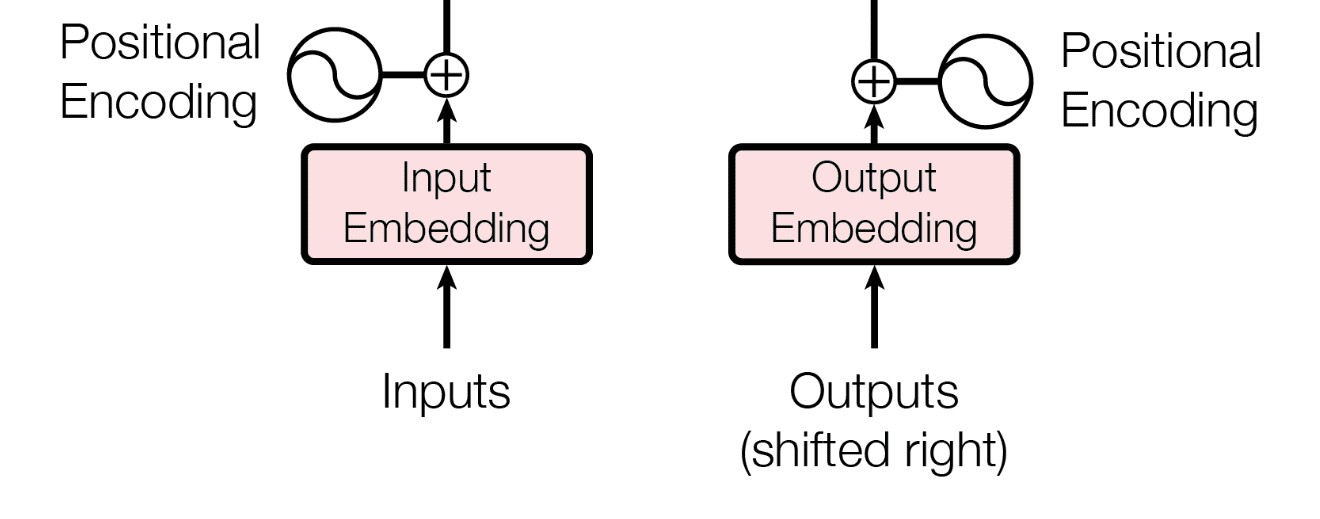
트랜스포머 모델은 입력 시퀀스를 일련의 벡터로 변환해 처리합니다. 그러나 모델은 순서 정보를 자동으로 감지하지 못하기 때문에, 순서를 명시하지 않으면 'this is a cat'과 'cat a is this'를 구별할 수 없습니다.
즉, 모델에게 두 시퀀스가 동일한 벡터 표현을 가질 수 있음을 구분할 수 있는 정보가 없습니다. 이러한 문제를 해결하기 위해 트랜스포머는 포지셔널 인코딩을 활용합니다. 포지셔널 인코딩은 각 입력 요소의 절대적 또는 상대적 위치 정보를 모델에 제공하는 역할을 하며, 입력 벡터와 같은 차원을 가지고 각 입력 벡터에 추가됩니다. 이를 통해 모델은 문장 내 각 단어의 위치를 인지하고, 따라서 문장의 구조와 의미를 보다 정확하게 파악할 수 있게 됩니다.
예를 들어, 'the boy who was bitten by the dog'와 'the dog who bit the boy'는 같은 단어들을 포함하지만 서로 다른 의미를 가집니다. 포지셔널 인코딩은 이와 같은 순서의 차이를 모델이 감지하게 하여 정확한 의미를 추론하도록 도와줍니다.
인코더 (Encoder)

인코더는 입력 시퀀스를 받아 처리하고, 디코더로 정보를 전달합니다. 인코더의 각 레이어는 다음과 같은 서브-레이어로 구성됩니다.
멀티 헤드 어텐션 Multi-Head Attention
멀티 헤드 어텐션 메커니즘은 입력 데이터에서 동시에 여러 위치의 정보를 취합합니다.
이 과정에서 모델은 서로 다른 단어 간의 관계를 더욱 효과적으로 파악할 수 있습니다.
각각의 'head'는 입력 데이터의 특정 부분에 초점을 맞추어, 다양한 문맥적 힌트를 동시에 제공합니다. 이렇게 수집된 정보는 결합되어, 모델이 입력 시퀀스 내의 단어들 사이에 존재하는 복잡한 상호작용을 정교하게 모델링하는 데 기여합니다.
잔차연결과 정규화 Add & Norm (Residual Connection and Layer Normalization)
멀티 헤드 어텐션의 출력에 잔차 연결(Residual Connection)을 추가한 후, 레이어 정규화(Layer Normalization)를 수행합니다.
잔차 연결은 입력값을 어텐션의 출력값에 직접 더하는 과정입니다. 이는 모델이 더 깊어질 때 발생할 수 있는 학습의 어려움을 완화시키기 위해 도입되었습니다.
레이어 정규화는 각 레이어의 출력을 정규화 하는 과정으로, 각 레이어의 평균과 분산을 사용합니다. 이 과정은 각 레이어에서 출력값의 분포가 일정하도록 유지함으로써 학습 과정을 안정화시킵니다.
결론적으로 잔차 연결과 레이어 정규화는 심층 신경망이 더 깊어질 때 발생할 수 있는 학습 문제를 완화하는 데 중요한 역할을 합니다. 이러한 기법들 덕분에 트랜스포머 모델은 깊은 아키텍처를 가짐에도 불구하고 빠르고 효과적으로 학습할 수 있습니다.
피드 포워드 Feed Forward
각 위치에 대한 정보를 개별적으로 처리하는 간단한 퍼셉트론 스타일의 네트워크로 비선형 변환을 제공합니다.
Feed Forward 레이어는 트랜스포머 모델이 복잡한 데이터 패턴을 포착하고, 보다 높은 수준의 추상화를 달성할 수 있도록 기여합니다.
이러한 방식으로 트랜스포머는 문맥적 의미를 포함한 더 풍부한 데이터 표현을 생성할 수 있습니다.
잔차연결과 정규화 Add & Norm
피드 포워드 네트워크의 출력에 다시 잔차 연결을 추가하고 레이어 정규화를 수행합니다. 이는 멀티 헤드 어텐션 출력에 연결한 것과 동일한 역할을 수행합니다.
인코더의 마지막 레이어를 거친 후, 최종 출력이 생성됩니다. 이 출력은 인코더가 입력 데이터에서 학습한 모든 중요한 정보를 포함합니다. 이 최종 출력은 디코더로 전달되어, 디코더가 타깃 시퀀스(예: 번역된 문장)를 생성하는 데 사용됩니다.
디코더 (Decoder)

디코더는 인코더로부터의 출력과 이전에 생성된 출력을 받아 다음 출력을 생성합니다.
디코더의 각 레이어에는 시작과 끝 부분에 포지셔널 인코딩이 추가됩니다. 이를 통해 시퀀스 내 각 단어의 위치 정보가 반영됩니다.
디코더 또한 다음과 같은 여러 서브-레이어로 구성됩니다.
마스크드 멀티 헤드 어텐션 Masked Multi-Head Attention
디코더의 마스크드 멀티 헤드 어텐션은 출력 시퀀스를 입력으로 받지만, '마스킹(masking)'이라는 기법을 사용해 아직 생성되지 않은 부분에 대한 정보는 차단합니다. 이는 모델이 미래의 단어를 예측하는 데 영향을 받지 않도록 하는 데 필요합니다.
즉, Masked Multi-Head Attention을 통해 디코더는 각 단어를 예측할 때 현재까지 생성된 시퀀스에만 의존하게 되므로, 모델은 실제 인간의 언어 생성 과정과 유사한 방식으로 작동하게 됩니다. 이는 모델이 더 현실적이고 일관된 텍스트를 생성할 수 있도록 도와줍니다.
잔차연결과 정규화 Add & Norm
Masked Multi-Head Attention 수행 후에 잔차 연결과 레이어 정규화를 수행합니다. 역할은 인코더의 Add & Norm과 동일합니다.
멀티 헤드 어텐션 Multi-Head Attention
이 멀티 헤드 어텐션 레이어는 인코더의 출력을 이용하며, 인코더와 디코더 사이의 연결고리 역할을 합니다.
이 레이어의 주요 목적은 인코더로부터 전달된 정보(인코더의 출력)를 활용하여 디코더가 출력 시퀀스를 더 잘 생성할 수 있도록 하는 것입니다.
해당 멀티 헤드 어텐션은 인코더의 각 단어(또는 문장 부분)와 디코더의 현재 단어(또는 생성 중인 문장 부분) 간의 관계를 파악하는 데 중점을 둡니다.
잔차연결과 정규화 Add & Norm
멀티 헤드 어텐션 이후 잔차 연결과 레이어 정규화를 다시 수행합니다.
피드 포워드 Feed Forward
디코더의 피드 포워드는 인코더와 동일한 피드 포워드 네트워크를 사용합니다.
잔차연결과 정규화 Add & Norm
마지막으로 잔차 연결과 레이어 정규화를 수행합니다.
디코더의 최종 출력
디코더의 최종 출력은 리니어 레이어를 거쳐 각 단어에 대한 점수를 산출하고, 이 점수들은 소프트맥스 함수에 의해 확률로 전환됩니다. 디코더의 각 단계는 이전 단계의 출력에 기반하며, 이는 각 단어가 이전 단어들과 어떻게 상호작용하는지를 반영합니다. 이러한 연속적인 처리 과정은 모델이 일관된 문장을 생성하는 데 중요한 역할을 합니다.
지금까지 트랜스포머 모델의 인코더, 디코더 구조에 대해서 좀 더 상세히 알아보았습니다.
다음 포스팅에서는 트랜스포머의 훈련과 추론 과정에 대해서 이야기 해보겠습니다.
트랜스포머
2. 트랜스포머 구조 (Transformer High-level Architecture)
3. 트랜스포머 구조 상세 (Transformer Detailed Architecture)
4. 트랜스포머 훈련과 예측 단계 (Transformer Learning and Inference Step)
5. 트랜스포머 입력과 출력 (Transformer Input and Output)
6. 어텐션, 셀프 어텐션, 멀티 헤드 어텐션 개요 (Transformer Attention, Self Attention, Multi-head Attention)
7. 셀프 어텐션 상세 동작 과정 (Transformer Self Attention Detailed Process)
8. 멀티 헤드 어텐션 상세 동작 과정 (Transformer Multi-head Attention Detailed Process)
BERT
Comment