
1. 트랜스포머 훈련과 예측 스텝 1
2. 트랜스포머 훈련과 예측 스텝 2
3. 트랜스포머 훈련과 예측 스텝 3

이번 포스팅에서는 트랜스포머가 어떤 순서로 훈련과 예측을 수행하는지 알아보겠습니다.
1. 트랜스포머 훈련과 예측 스텝 1
트랜스포머 모델이 '어제 카페 갔었어'라는 한글 문장을 영어로 번역하는 과정을 살펴보겠습니다. 이 과정을 통해 트랜스포머의 훈련과 예측이 어떤 과정을 거치는지 이해할 수 있습니다.
- 인코더 입력: 한글 소스 시퀀스 전체
- 디코더 입력: 인코더의 출력 + <s> 토큰 (시작 스페셜 토큰)
- 최종 출력: 영어 번역 출력 I
이 단계에서 인코더는 한글 문장을 처리해 디코더로 전달하고, 디코더는 이 정보와 시작 토큰을 바탕으로 첫 번째 영어 단어 'I'를 예측합니다.
좀 더 자세히 설명하면 인코더는 입력 소스 시퀀스를 압축해 디코더로 보내고, 디코더는 인코더에서 보내온 정보와 현재 디코더 입력을 모두 고려해 다음 토큰(I)를 맞추는 과정을 수행합니다. 그리고, 결과적으로 트랜스포머의 출력은 입력 시퀀스와 시작 토큰을 보고 I의 토큰을 반환합니다.
2. 트랜스포머 훈련과 예측 스텝 2
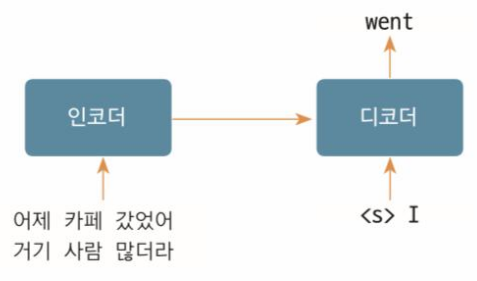
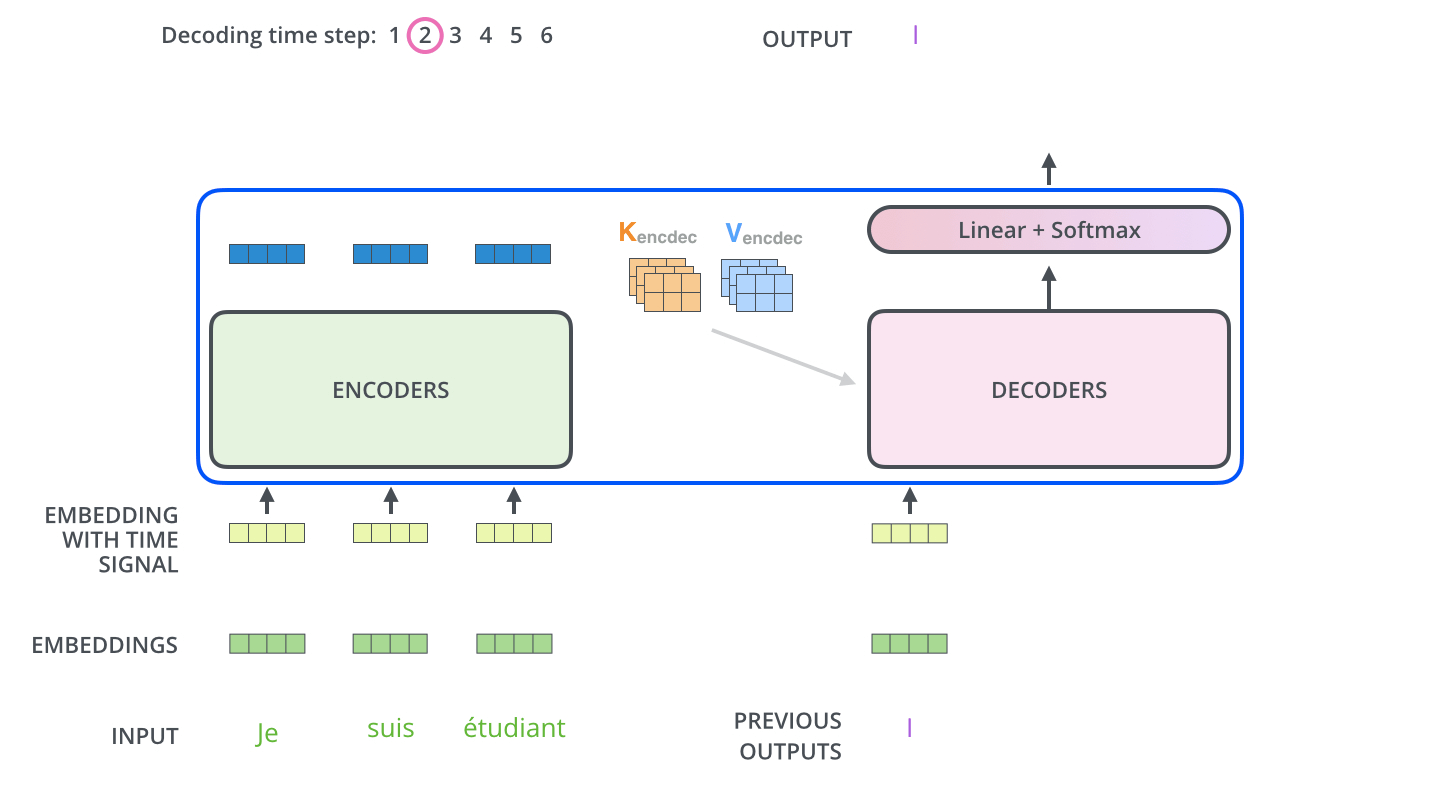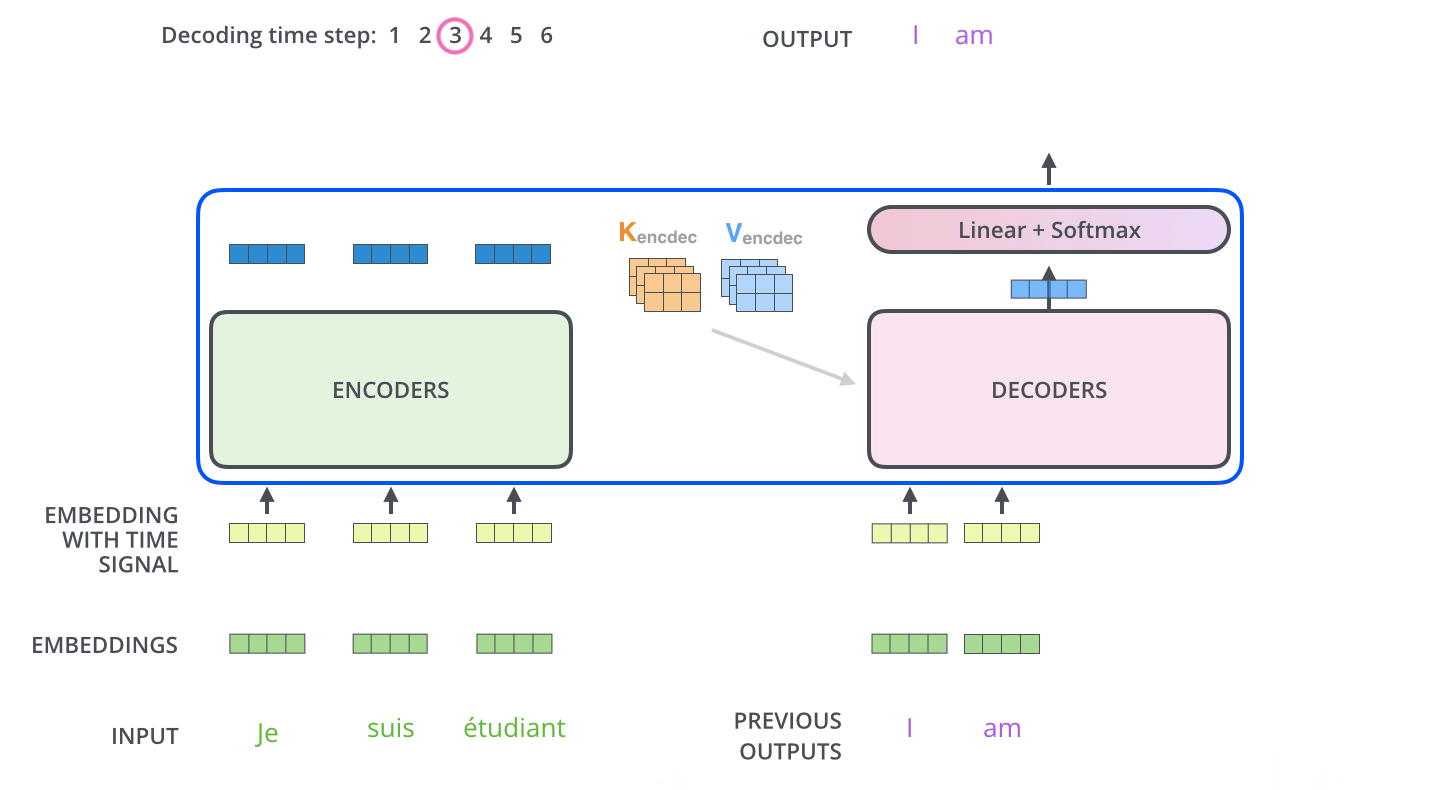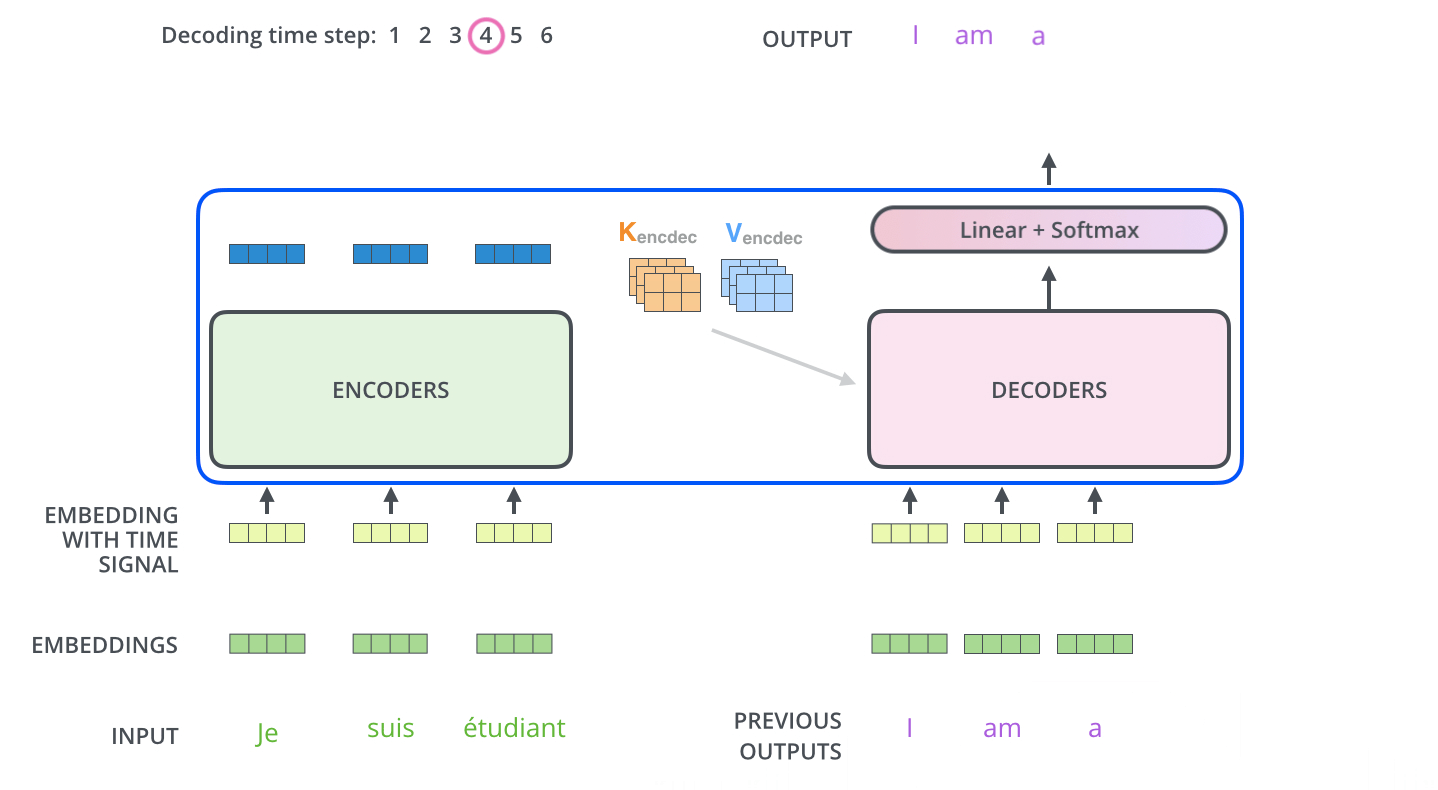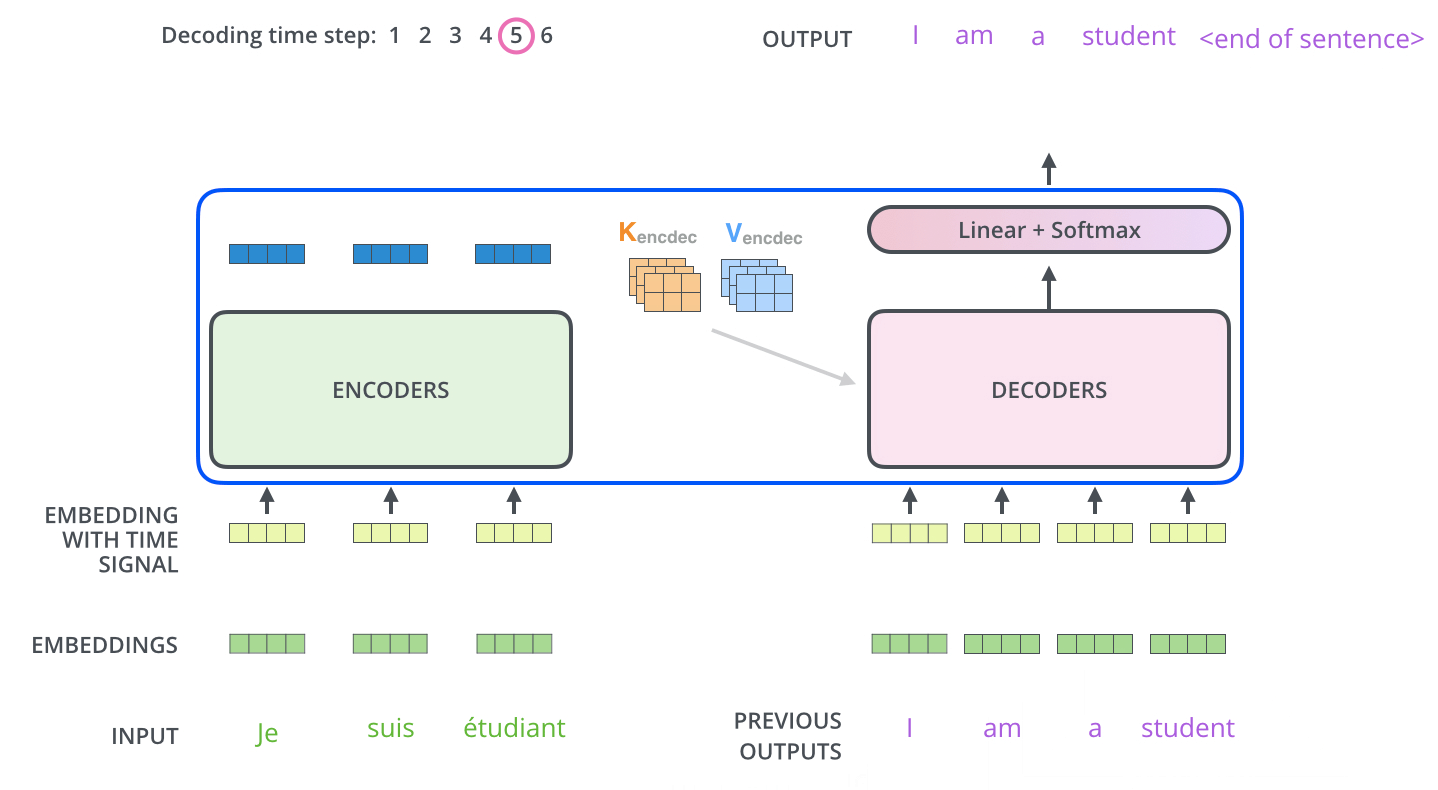
- 인코더 입력: 한글 소스 시퀀스 전체
- 디코더 입력: 인코더의 출력 + <s> I (이전 디코더 출력)
- 최종 출력: 영어 번역 출력 went
이 시점에서는 'I'를 포함한 이전 단계의 출력을 디코더 입력으로 사용하여, 훈련 시 전체 문맥을 고려하고, 예측 시에는 이를 바탕으로 'went'를 예측합니다. 또한 예측시에는 직전 디코더의 출력 결과만 사용하여 바로 다음에 나올 토큰이 어떤 토큰인지를 적절하게 예측하도록 합니다.
3. 트랜스포머 훈련과 예측 스텝 3
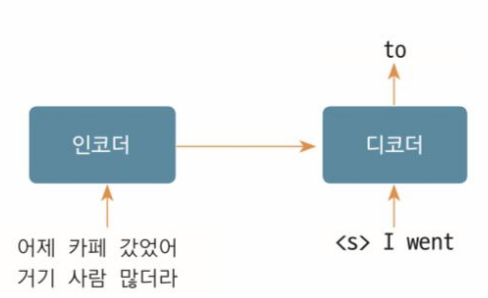
- 인코더 입력: 한글 소스 시퀀스 전체
- 디코더 입력: 인코더의 출력 + <s> I went (이전 디코터 출력)
- 최종 출력: 영어 번역 출력 to
이 단계에서는 'I went' 시퀀스를 바탕으로 다음 단어 'to'를 예측합니다. 훈련 중에는 모델이 문장의 앞뒤 문맥을 고려한 정답 확률을 높이기 위해 지속적으로 조정되고, 예측 시에는 현재까지의 디코더 출력을 기반으로 다음 단어를 예측합니다.
즉, 인코더는 모든 소스 시퀀스를 입력으로 받고, 디코더에서는 훈련 시와 예측 시에 각각 다른 입력을 가지고 출력 토큰을 예측합니다. 훈련 단계에서는 전체 문맥 이해를 위해서 디코더의 이전 출력값 모두를 디코더의 입력으로 넣는 것이고, 예측 단계에서는 정확한 예측을 위해서 디코더의 직전 출력값만 넣어서 예측하는것 입니다.
이러한 방식으로 트랜스포머 모델은 훈련 단계에서 전체 문맥을 학습하고, 예측 단계에서는 현재까지의 출력에 기반해 적절한 다음 단어를 예측합니다. 이 과정을 반복하며 모델은 점점 더 정확하고 자연스러운 번역을 생성할 수 있게 됩니다.
인코더와 디코더의 처리 과정을 잘 나타내는 그림을 첨부합니다.
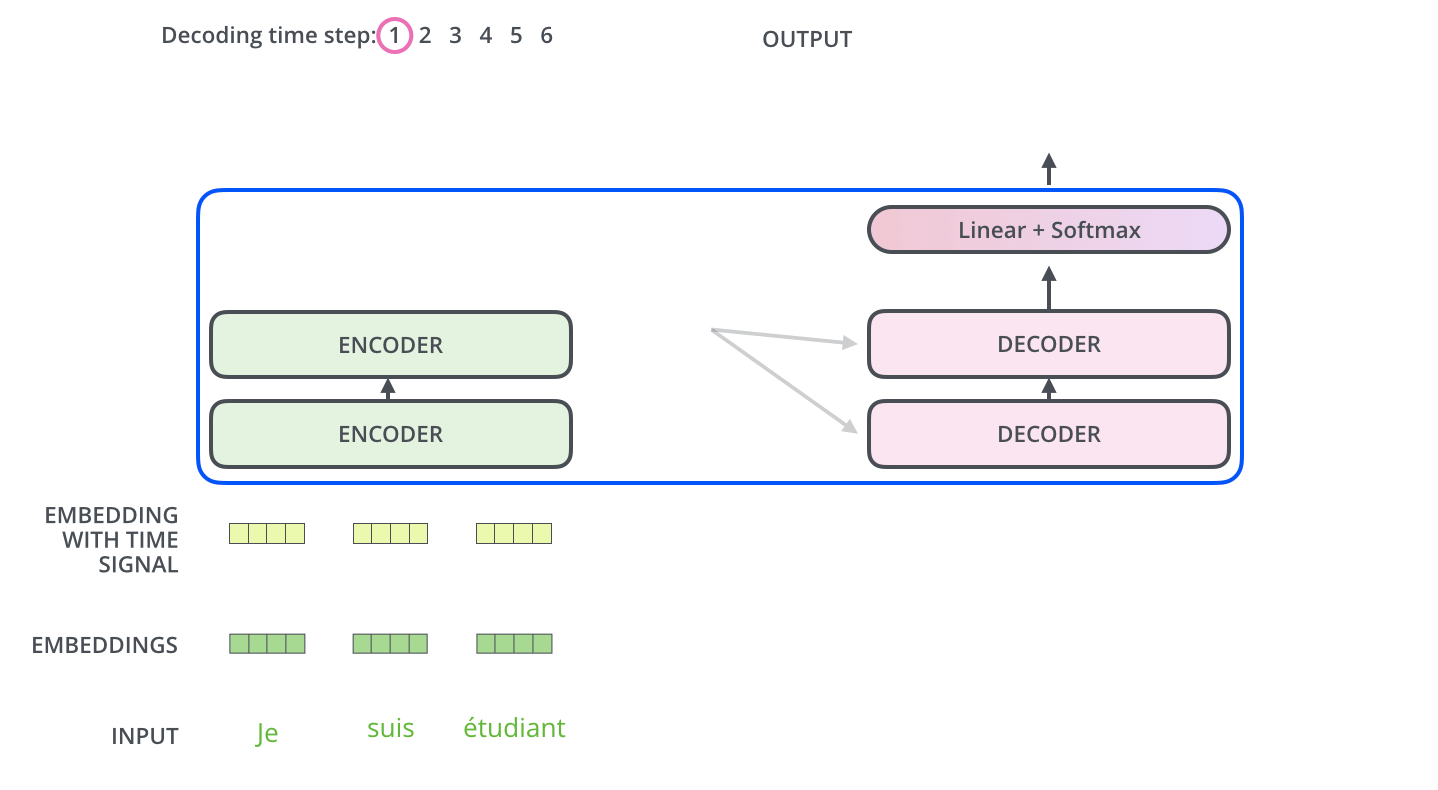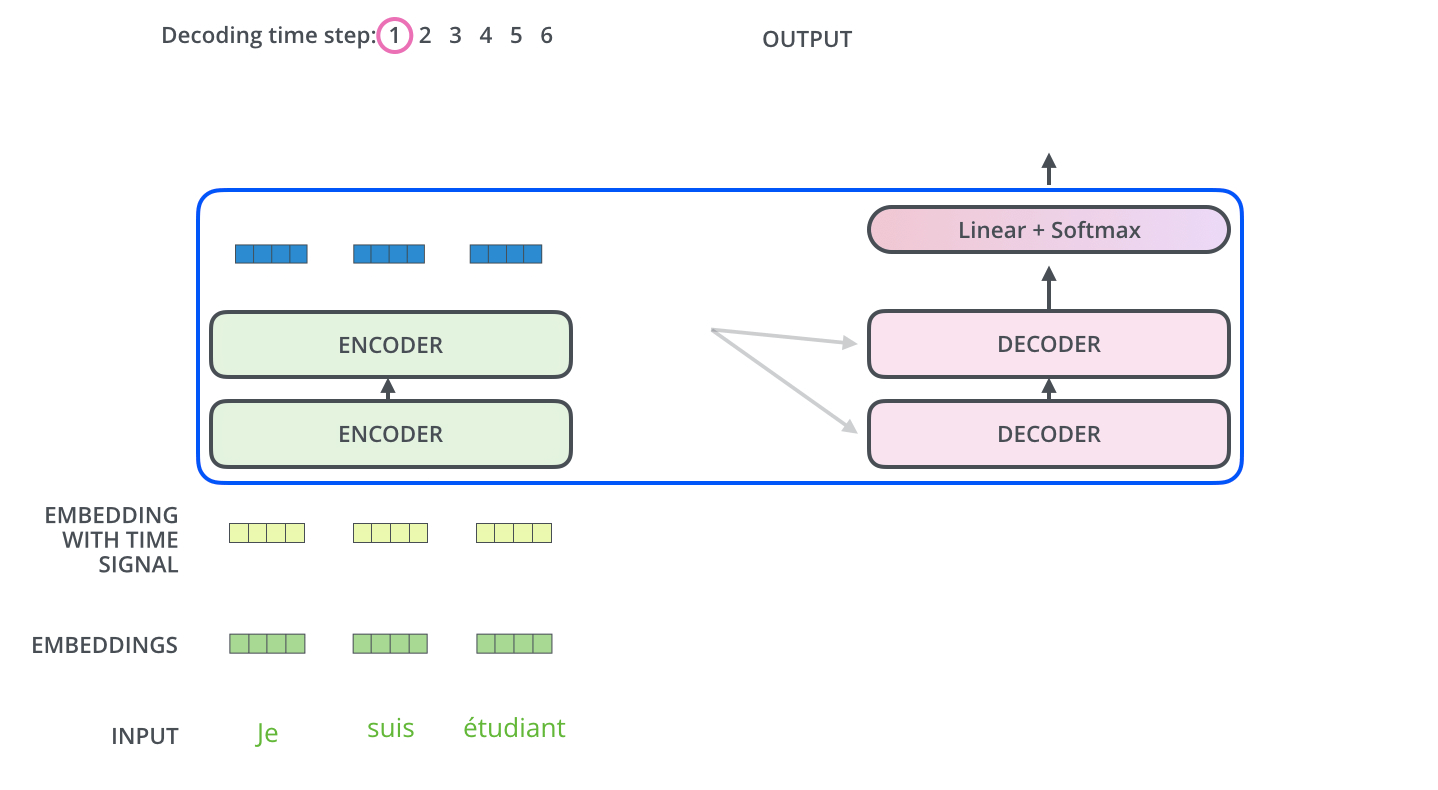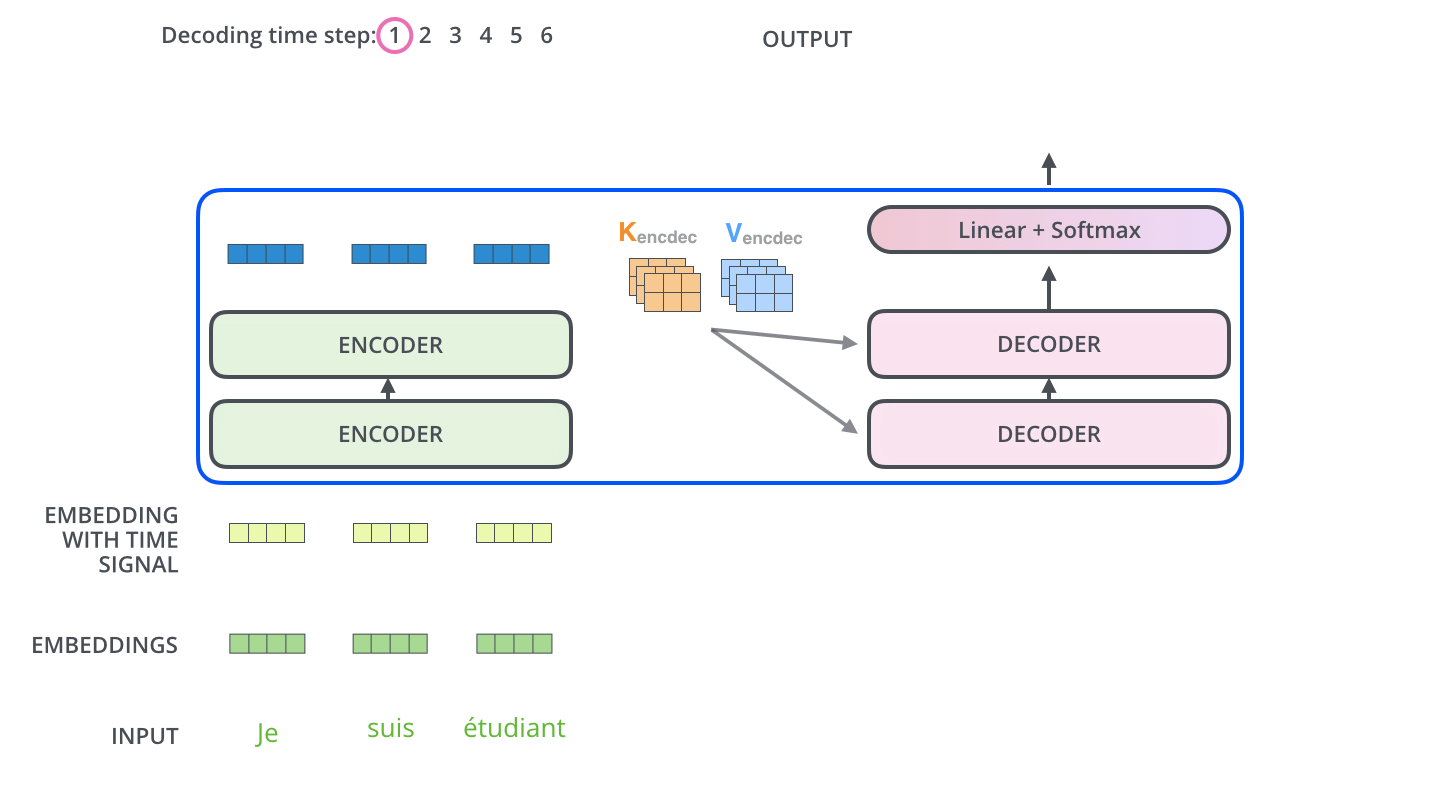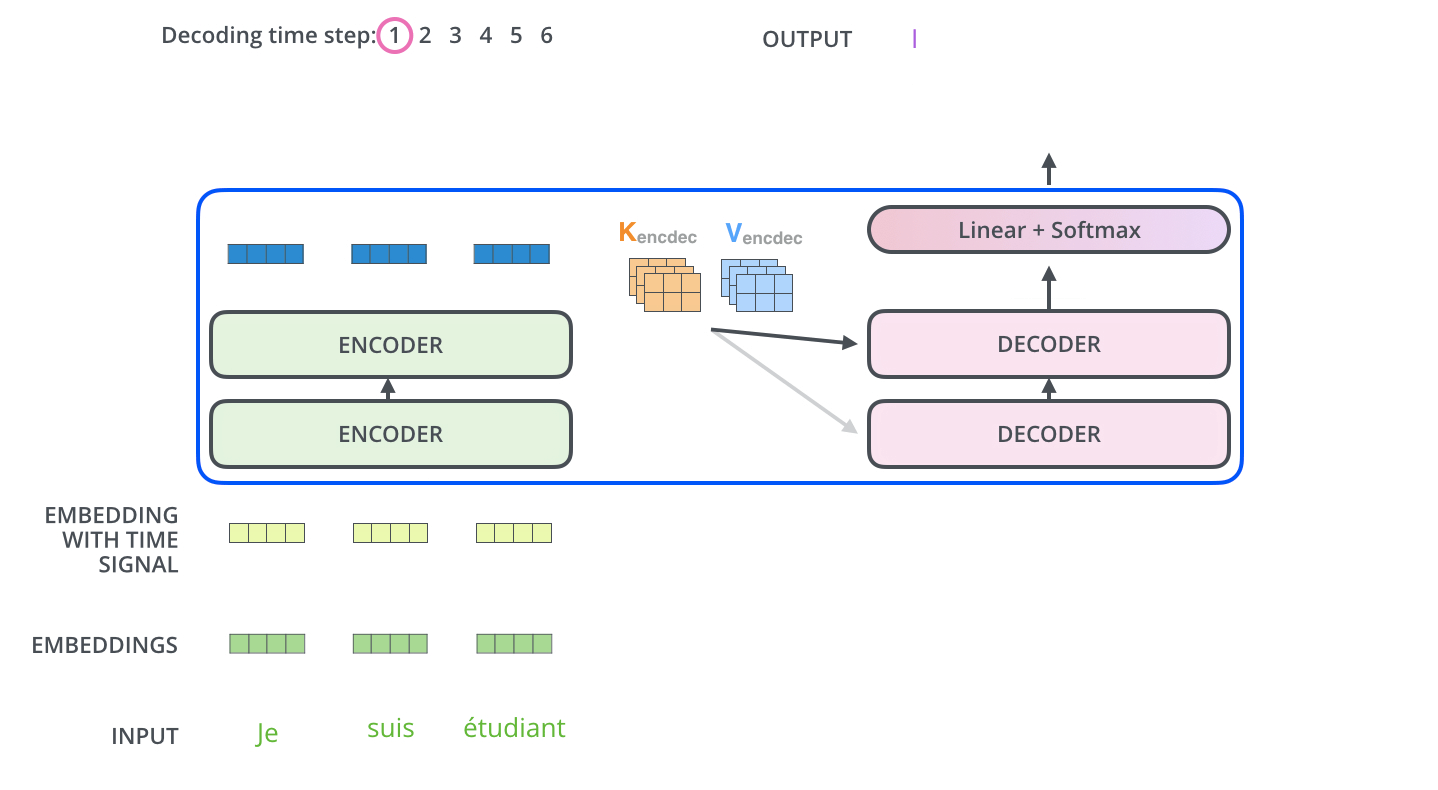
이상 트랜스포머가 훈련과 예측 단계에서 어떻게 동작하는지 알아보았습니다. 다음 포스팅에서는 트랜스포머의 각 구성 요소들을 더 자세히 알아보겠습니다.
트랜스포머
2. 트랜스포머 구조 (Transformer High-level Architecture)
3. 트랜스포머 구조 상세 (Transformer Detailed Architecture)
4. 트랜스포머 훈련과 예측 단계 (Transformer Learning and Inference Step)
5. 트랜스포머 입력과 출력 (Transformer Input and Output)
6. 어텐션, 셀프 어텐션, 멀티 헤드 어텐션 개요 (Transformer Attention, Self Attention, Multi-head Attention)
7. 셀프 어텐션 상세 동작 과정 (Transformer Self Attention Detailed Process)
8. 멀티 헤드 어텐션 상세 동작 과정 (Transformer Multi-head Attention Detailed Process)
BERT
Comment