

이번 포스팅 부터는 구글에서 발표한 언어 모델인 BERT(Bidirectional Encoder Representations from Transformers)에 대해서 알아보겠습니다.
BERT란 어떤 언어 모델이고, 어떤 특징을 가지고 있으며, 어떻게 동작하는지 하나 하나 살펴볼 예정입니다.
BERT(Bidirectional Encoder Representations from Transformers) 란?
2019년도에 Google AI Language가 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019)에서 발표한 논문(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)에 처음으로 소개된 언어 모델로 자연어처리 (NLP) 모델로 대량의 텍스트 데이터로 부터 문맥적 의미를 학습하여 각 단어의 양방향 문맥을 파악하는데 강점을 가지고 있습니다.
BERT의 특징
BERT (Bidirectional Encoder Representations from Transformers)는 위키 백과와 같은 대용량의 레이블이 지정되지 않은 데이터(unlabeled data)를 사용해 언어 모델을 사전 학습(pretraning)한 전이 학습(transfer learning) 모델입니다. BERT는 이렇게 다량의 단어 임베딩(word embedding)을 사전학습한 모델을 특정 목적에 맞는 레이블이 지정된 데이터(labeled data)를 미세 조정(fine-tuning)하여 문서 분류, 질의 응답, 개체명 인식 등과 같은 다양한 자연어 처리(NLP) 작업을 수행할 수 있는 모델 입니다.
- 전이학습 모델
- 사전학습으로 대용량의 언어를 학습하고, 미세조정을 통해 특정 Task를 수행할 수 있는 모델

BERT에서 사전학습과 미세조정
BERT에서 사용하고 있는 사전학습(Pre-training)과 미세조정(Fine-tuning)에 대해서 간략하게 알아보겠습니다.
BERT에서의 사전학습(Pre-training)
사전학습 단계에서 BERT는 레이블 되지 않은 대용량의 데이터를 기반으로 한 워드 임베딩을 학습합니다. 이 때 BERT는 주어진 문맥 안에서 단어의 의미를 이해할 수 있도록 설계된 두 가지 주요 작업을 수행합니다.
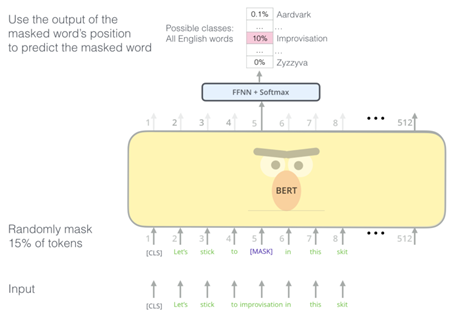
첫 번째는 Masked Language Model(MLM) 작업입니다. MLM은 문장 내에서 임의의 단어들을 가리고(마스킹) BERT가 이를 예측하도록 합니다. 예를 들어 “나는 학교에 간다.” 라는 문장에서 “학교”라는 단어를 가리고 BERT가 이를 예측하도록 합니다. 이를 통해 모델은 단어의 양방향 문맥을 이해하여 적절한 단어를 예측하도록 하는 능력을 키우는 방향으로 학습합니다.

두 번째는 Next Sentence Prediction(NSP) 작업입니다. NSP는 두 문장이 순차적인 관계에 있는지를 예측합니다. 예를 들어 “나는 학교에 간다. 그리고 친구를 만났다”라는 두 문장이 순차적으로 연결되어 있는지를 BERT가 예측합니다. 이를 통해 BERT는 두 문장 간의 관계에 대해 이해하는 학습을 하게 되어 다양한 자연어 처리 작업에서의 문맥 이해 능력이 향상됩니다. 이러한 능력은 특히 질문응답, 자연어 추론, 문서 요약 등에서 중요한 역할을 합니다. 또한, 이 과정은 BERT가 더 복잡한 텍스트 구조를 파악하고, 텍스트 내의 다양한 정보를 연결짓는 방법을 학습하는 데 도움을 주어 문장간 의미적 관계를 더 잘 파악할 수 있도록 합니다.
BERT에서의 미세조정(Fine-tuning)
미세조정은 다량의 데이터를 이용하여 사전 학습된 BERT 모델을 특정 자연어 처리(NLP) 작업에 맞게 조정하는 과정입니다. 이를 통해 특정 작업에 특화된 모델을 생성할 수 있습니다.

미세 조정은 원하는 특정 작업에 대한 레이블이 지정된 데이터를 사용하여 모델을 추가로 학습시키는 작업 자체를 의미합니다. 이 단계에서 모델의 모든 파라미터나 일부 파라미터를 조정하여 특정 작업에 적합하도록 만듭니다. 예를 들어, 문서 분류, 질의응답, 번역과 같은 작업에서 BERT 모델은 사전 학습을 통해 습득한 언어 이해 능력을 바탕으로 특정 작업에 필요한 세부적인 패턴이나 규칙을 학습합니다. 이를 통해 학습시간이 단축되고 상대적으로 적은 데이터로도 자연어 처리를 충분히 수행할 수 있게 됩니다.
지금까지 BERT에 대해서 간략하게 알아보았습니다. 다음 포스팅 부터 BERT에 대해서 자세히 알아볼 예정입니다.
트랜스포머
2. 트랜스포머 구조 (Transformer High-level Architecture)
3. 트랜스포머 구조 상세 (Transformer Detailed Architecture)
4. 트랜스포머 훈련과 예측 단계 (Transformer Learning and Inference Step)
5. 트랜스포머 입력과 출력 (Transformer Input and Output)
6. 어텐션, 셀프 어텐션, 멀티 헤드 어텐션 개요 (Transformer Attention, Self Attention, Multi-head Attention)
7. 셀프 어텐션 상세 동작 과정 (Transformer Self Attention Detailed Process)
8. 멀티 헤드 어텐션 상세 동작 과정 (Transformer Multi-head Attention Detailed Process)
BERT
Comment