
1. 비지도 학습이란? (Unsupervised Learning)
2. 비지도 학습의 종류 (Types of Unsupervised Learning)
2.1. 군집화 (Clustering)
2.2. 차원 축소 (Dimensionality Reduction)
2.3. 연관 규칙 학습 (Association Rule Learning)
2.4. 이상치 탐지 (Novelty (Anomaly) Detection)

이번 포스팅에서는 머신러닝의 학습 방법 중 비지도 학습 (Unsupervised Lenarning)에 대해서 알아보겠습니다.
1. 비지도 학습이란? (Unsupervised Learning)
비지도 학습은 훈련 데이터에 정답 레이블이 없이 모델이 스스로 데이터의 구조와 패턴을 학습하는 방식으로 시스템이 어떤 지도나 감독 없이 스스로 데이터를 분석하고 구조를 발견하는 방법으로 데이터에서 숨겨진 구조를 발견하고 이해하는 데 중점을 두며, 레이블이 없는 데이터로부터 의미있는 정보를 추출합니다.
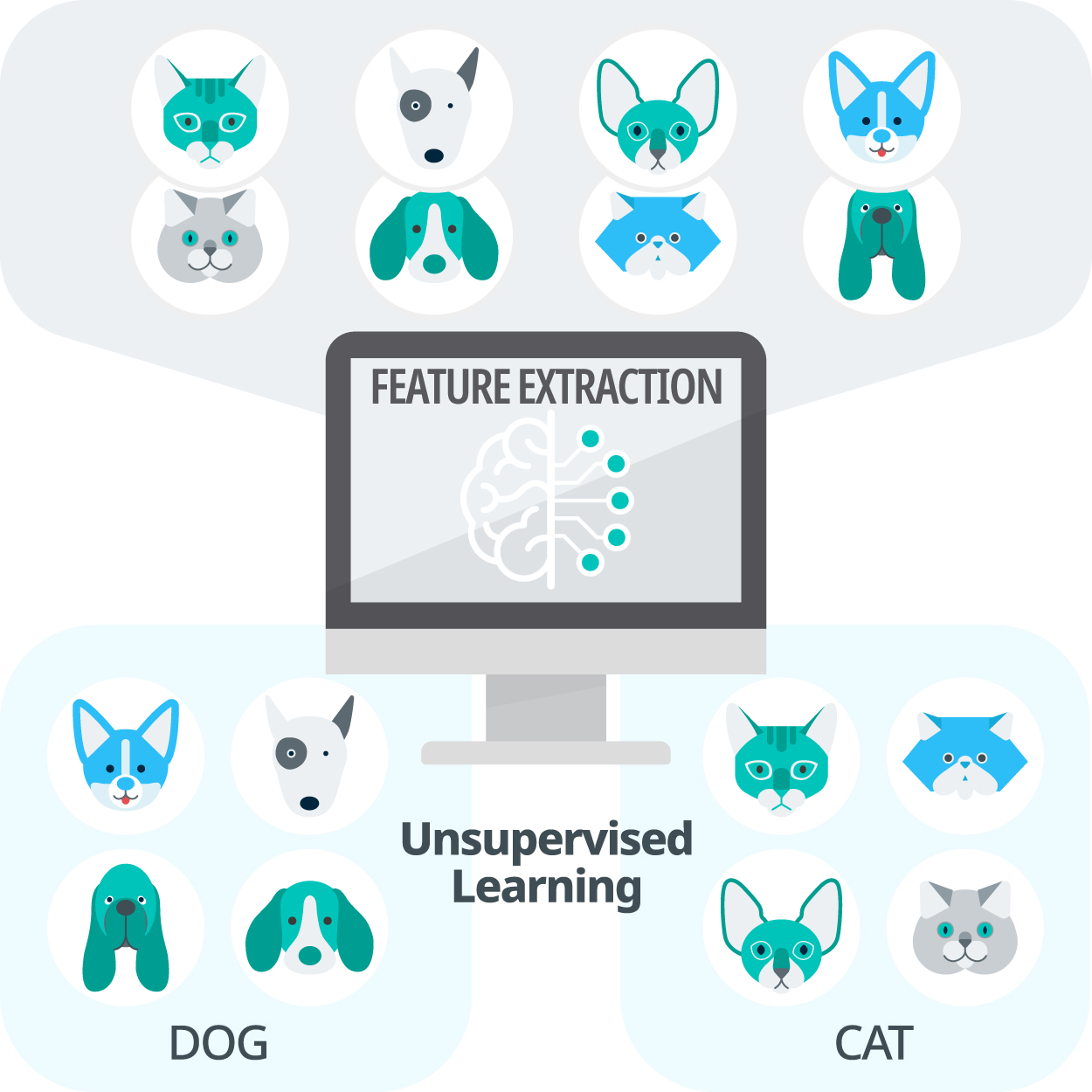
비지도 학습은 레이블이 없어 지도 학습처럼 명확하지 않기 때문에 모델의 성능평가가 어렵습니다. 또한, 사용자가 직접 모델을 해석하고 정답, 규칙을 추론하여 이를 활용해야 하기 때문에 사용자의 주관에 크게 의존할 수도 있는 특징이 있습니다.
비지도 학습은 복잡한 데이터셋에서 숨겨진 인사이트를 발견하거나, 데이터의 전처리 과정에서 차원을 축소하는 것과 같은 중요한 역할을 하며, 레이블이 부족하거나 데이터의 탐색적 분석이 필요할 때 유용합니다. 또한, 데이터에서 비정상적인 패턴이나 이상치를 식별하는데 사용할 수 있습니다.
2. 비지도 학습의 종류 (Types of Unsupervised Learning)
비지도 학습의 대표적인 방법은 군집화 (Clustering)과 차원 축소 (Dimensionality Reduction)이 있습니다.
2.1. 군집화 (Clustering)
군집화는 데이터를 비슷한 특성을 가진 여러 그룹으로 분류하는 방법입니다.
군집화의 목적은 데이터 내에 존재하는 자연스러운 구분을 찾아 각 클러스터 내의 데이터 포인트들이 서로 유사하고, 클러스터 간에는 서로 다르게 만드는 것입니다.
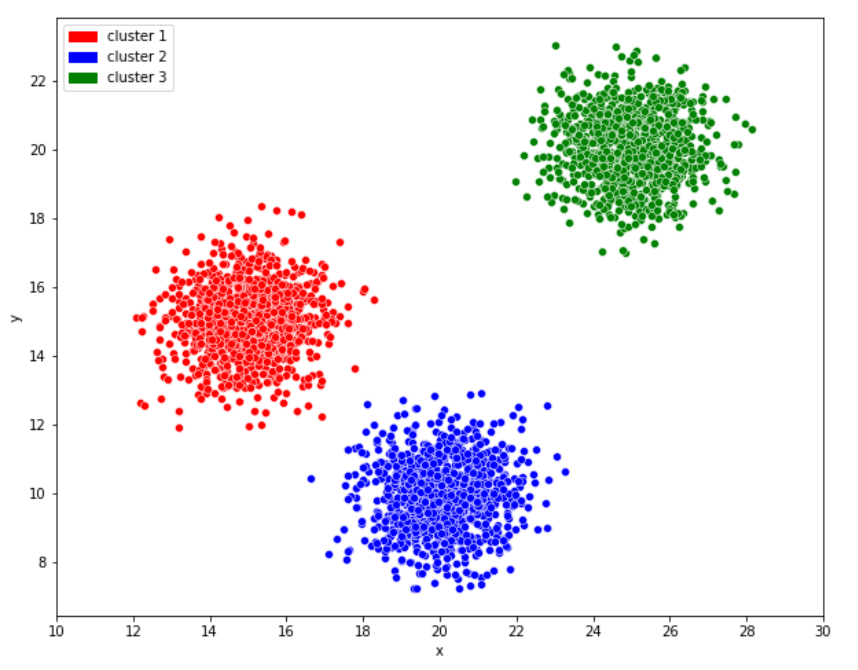
군집을 형성하는 방법에 따라 계층적 군집 (Hierarchical Clustering), 분할적 군집 (Partional Clustering), 분포 기반 군집 (Distribution-based Clustering), 밀도 기반 군집 (Density-based Clustering) 등이 있습니다.
2.2. 차원 축소 (Dimensionality Reduction)
차원 축소는 데이터의 차원을 축소하여 데이터의 가장 중요한 정보를 보존하는 새로운 차원을 찾는 방법입니다. 즉, 고차원 데이터에서 중요한 정보를 유지하면서 차원의 수를 줄이는 과정입니다.
차원 축소의 주된 목적은 데이터의 복잡성을 감소시키고, 계산 효율성을 높이며, 데이터의 시각화를 용이하게 하는 것입니다.
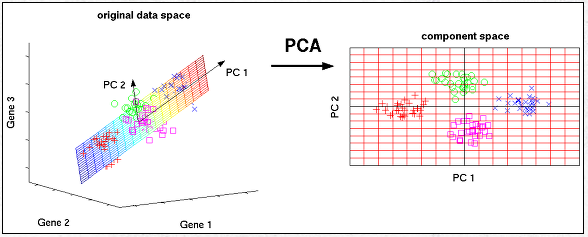
대표적인 방법으로 주성분 분석 (PCA)가 있습니다.
2.3. 연관 규칙 학습 (Association Rule Learning)
연관 규칙 학습은 대규모 데이터에서 항목 간의 관계를 식별하는 방법입니다. 즉, 데이터셋에서 항목 간의 관심있는 연관성이나 빈번하게 발생하는 패턴을 식별하는 방법입니다. 주로 대규모 거래 데이터베이스에서 유용한 규칙들을 발견하는 데 사용되며, 이 규칙들은 항목 간의 강력한 관계를 나타냅니다.
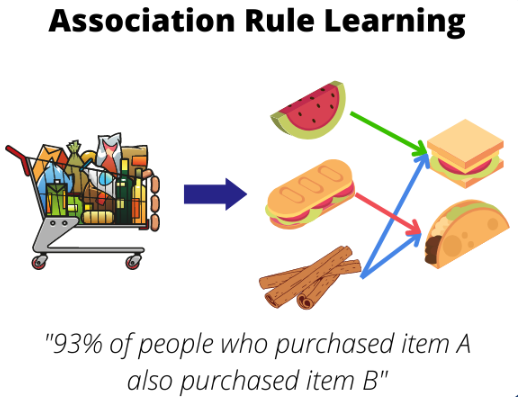
대표적인 방법으로는 장바구니 분석(Apriori) 방법이 있습니다.
2.4. 이상치 탐지 (Novelty (Anomaly) Detection)
이상치 탐지는 데이터셋에서 일반적인 패턴에서 벗어나는 데이터 포인트, 즉 이상치를 식별하는 과정으로 정상적인 패턴을 학습하고, 이 패턴과 크게 달라지는 경우를 이상치로 간주하는 방법입니다.
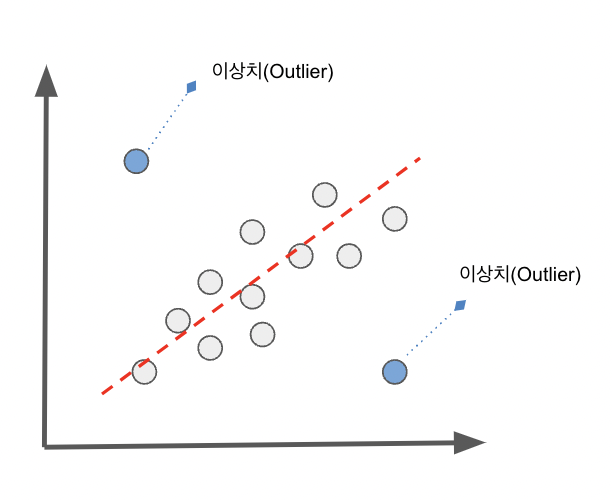
대표적인 알고리즘으로 아이솔레이션 포레스트 (Isolation Forest), LOF (Local Outlier Factor), 오토인코더 (Autoencoder) 등이 있습니다.
이상 비지도 학습에 대한 포스팅을 마치며, 다음 포스팅 부터는 지도학습, 비지도학습의 대표적인 알고리즘들을 자세하게 알아보겠습니다.
머신러닝(Machine Learning)
1. 머신러닝이란? (Machine Learning?)
2. 머신러닝 학습 방법 - 지도학습 (Supervised Learning)
3. 머신러닝 학습 방법 - 비지도학습 (Unsupervised Learning)
Comment