
1. read_csv 옵션으로 제거하기
2. drop으로 제거하기
728x90

pandas로 csv 파일을 읽어오면 인덱스 열이 맨 첫번째 컬럼으로 들어갑니다.
위와 같은 csv의 인덱스 컬럼을 제거하는 방법을 알아보겠습니다.
1. read_csv 옵션으로 제거하기
pandas 패키지의 read_csv를 이용하면 csv 파일을 읽어와서 데이터 프레임으로 바로 변환합니다. 이때 index_col 옵션을 이용하면 위와 같은 인덱스 컬럼을 제거할 수 있습니다.
import pandas as pd
df = pd.read_csv("data.csv", index_col=0)
dfpythondata.csv 파일을 읽어서 df 데이터 프레임을 만드는 코드입니다. 이때 index_col 값을 0으로 지정하면 Unnamed: 0 컬럼이 없어집니다.
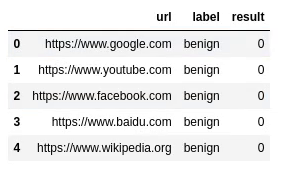
이미 csv 파일을 로드하여 데이터 프레임을 만들었으면 다음 방법으로 해당 컬럼을 없앨 수 있습니다.
2. drop으로 제거하기
pandas의 drop 메서드로 컬럼을 제거할 수 있습니다. 다음과 같이 첫번째 컬럼을 제거하는 코드로 Unnamed: 0 컬럼을 제거할 수 있습니다.
import pandas as pd
df = pd.read_csv("data.csv")
df = df.drop(df.columns[0], axis=1)
dfpython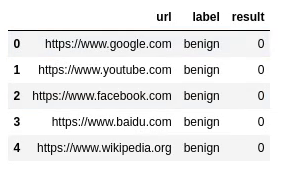
Unnamed: 0 컬럼이 없어졌음을 볼 수 있습니다. 반드시 drop 한 후에는 해당 데이터 프레임을 다시 원본 데이터 프레임이 넣어줘야 drop한 내용이 원본 데이터 프레임이 씌여 집니다.
아니면 drop 시 inplace 옵션을 사용할 수도 있습니다.
import pandas as pd
df = pd.read_csv("data.csv")
df.drop(['Unnamed: 0'], axis=1, inplace=True)
dfpythoninplace=True 옵션을 사용하면 원본 데이터 프레임에 drop한 내용을 넣지 않아도 바로 원본 데이터 프레임이 반영됩니다.
이상 pandas에서 read_csv 시 Unnammed: 0 인덱스 컬럼을 제거하는 방법을 알아보았습니다.
728x90
728x90
LIST
Comment